Czy sztuczna inteligencja jest inteligentna?
Czego dowiesz się z tego artykułu?
Artykuł jest dość obszerny, więc i dowiedzieć się można z niego wielu rzeczy. Głównym celem artykułu jest udzielenie odpowiedzi na tytułowe pytanie – czy AI jest inteligentne? W celu uzyskania odpowiedzi:
- poznasz historyczne i współczesne definicje inteligencji
- dowiesz się, jak powstaje sztuczna inteligencja, czym jest uczenie maszynowe, modele językowe i parametry sieci neuronowych
- spojrzysz na temat inteligencji z oryginalnych perspektyw, które pozwalają zakładać, że inteligencja może istnieć nawet poza biologiczną lub sztuczną siecią neuronową
- zobaczysz ciekawy test na inteligencje, który przeciętny człowiek wykonuje znacznie lepiej niż najlepsze AI
Dlaczego napisałem ten artykuł?
Przede wszystkim chciałem uporządkować własną wiedzę w zakresie inteligencji. Od lat pasjonuję się technologią i pracuję nad wdrożeniem sztucznej inteligencji w celu automatyzacji procesów rekrutacyjnych. Moim celem jest wdrożenie AI w systemie ATS w sposób, który uczyni rekruterów nadzorców tego procesu i uwolni użytkowników systemów rekrutacyjnych od żmudnego klikania.
Ponadto, zależy mi na tym, aby ludzie jak najlepiej rozumieli sztuczną inteligencję, albowiem jest to technologia przełomowa i w coraz większym stopniu przenika nasze życie. To przenikanie wywołuje czasem obawy, u niektórych osób nawet obawy egzystencjonalne. Obawy te mogą wynikać między innymi z niezrozumienia technologii sztucznej inteligencji. Tym artykułem postaram się to niezrozumienie usunąć.

Definicje inteligencji i słowniczek pojęć
Na pytanie, “Czy sztuczna inteligencja jest rzeczywiście inteligentna?” należy odpowiedzieć: “To zależy od przyjętej definicji inteligencji”.
Naukowcy spierają się, co do tego, czym jest inteligencja. W artykule przedstawię kilka z nich, które moim zdaniem są jednocześnie ciekawe, odmienne i pozwalają spojrzeć na problem z różnych perspektyw. Jednocześnie przedstawiam poniżej słowniczek, który wyjaśnia znaczenie technicznych pojęć pojawiających się w artykule.
Definicje inteligencji i słowniczek pojęć
- Uczenie maszynowe – kategoria algorytmów komputerowych, za pomocą których można budować systemy (modele) uczące się na podstawie danych.
- Uczenie się (w kontekście uczenia maszynowego) – proces, w którym system uczy się wykonywać zadania, takie jak rozpoznawanie obrazów czy przewidywanie wyników, na podstawie analizy danych. Zamiast być zaprogramowanym krok po kroku (klasyczny sposób tworzenia systemów komputerowych), system samodzielnie “uczy się” rozwiązywać problemy, korzystając z przykładów, które mu dostarczamy.
- Model – architektura systemu, wraz z konfiguracją jego parametrów, stworzona za pomocą uczenia maszynowego. Przykładem modelu jest GPT-4o stosowany w ChatGPT.
- Model językowy – model wyspecjalizowany w posługiwaniu się językiem naturalnym, np. ChatGPT, Claude i wiele innych.
- Parametry modelu – w uproszczeniu model to gigantyczny zbiór macierzy liczbowych. Gigantyczny, to znaczy, że te macierze zapisane są miliardami liczb. Wyobraź sobie wydrukowany plik excela, w którym każda komórka jest kwadratem o boku 1 cm. Model GPT4 wykorzystywany w ChatGPT ma mniej więcej 1.8 biliona parametrów i jego “excel” zająłby powierzchnię boiska piłkarskiego. Każda z komórek tego excela zawiera liczbę i ta liczba to właśnie parametr modelu.
- GPT – Generative Pre-trained Transformer – model sztucznych inteligencji wykorzystywany m.in. w ChatGPT. Wykorzystuje tak zwane transformery, za pomocą których model stosuje mechanizm uwagi. Dzięki mechanizmowi uwagi modele GPT potrafią rozumieć znaczenia słów i powiązań między słowami w różnych kontekstach. Wymyślenie transformerów i mechanizmu uwagi stanowiło przełom w rozwoju sztucznej inteligencji.
- Prompt – zapytanie, w formie tekstu, głosu, dokumentu, obrazu, dźwięku, kierowane do sztucznej inteligencji w celu uzyskania odpowiedzi na to zapytanie.
- Halucynacje – udzielanie przez model odpowiedzi z nieprawdziwymi informacjami lub nieprawdopodobnymi przewidywaniami. Halucynacje wynikają z faktu, że modele działają na zasadzie probabilistycznej. Oznacza to, że starają się udzielić odpowiedź, której poprawność jest najbardziej prawdopodobna. Najbardziej prawdopodobna odpowiedź nie zawsze jednak oznacza, że jest to odpowiedź prawidłowa.
- Multimodalność – zdolność przetwarzania przez model tekstu, obrazu i dźwięku.
Uwaga – czasem będę zamiennie używał pojęć sztuczna inteligencja, model, ChatGPT, bez wchodzenia w szczegóły różnic między tymi pojęciami. Dla przykładu ChatGPT to aplikacja, która wykorzystuje różne modele GPT, zatem różne modele sztucznej inteligencji. Sam ChatGPT to aplikacja, interfejs, za pomocą którego korzystamy z tych modeli. Dbająca o szczegóły ktoś mógłby powiedzieć, że ChatGPT to nie sztuczna inteligencja i miałby rację. Zdaję sobie z tego sprawę, ale świadomie upraszczam przekaz, aby artykuł był przystępny dla osób mniej zaznajomionych z technicznymi aspektami tego tematu.
Historia inteligencji i jej definicji
Pojęcie inteligencji ewoluowało na przestrzeni dziejów i kształtowane było przez myślicieli i badaczy od czasów starożytnych, do współczesnych. Początkowo definiowano ją jako zdolność do rozumienia, pojmowania i poznawania. W średniowieczu inteligencję wiązano z duszą i aniołami, podczas gdy w czasach Oświecenia postrzegano ją jako narzędzie do nabywania wiedzy i postępu.
W XIX wieku narodziła się psychologia naukowa, która zaczęła badać inteligencję w sposób bardziej systematyczny. Alfred Binet stworzył pierwsze testy IQ, które miały na celu mierzenie inteligencji dzieci. W XX wieku koncepcja inteligencji rozszerzyła się o nowe obszary, takie jak kreatywność, inteligencja emocjonalna i inteligencja społeczna.
Współczesne definicje inteligencji obejmują szeroki zakres zdolności, takich jak:
- Uczenie się i przyswajanie wiedzy
- Rozwiązywanie problemów i podejmowanie decyzji
- Myślenie abstrakcyjne i logiczne
- Planowanie i przewidywanie
- Język i komunikacja
- Tworzenie i innowacje
- Adaptacja do nowych sytuacji
- Zdolność do generalizacji.
Nie ma jednej, powszechnie akceptowanej definicji inteligencji. Różni badacze kładą nacisk na różne aspekty tej złożonej cechy. Istnieje również wiele różnych teorii inteligencji, które próbują wyjaśnić, jak ona działa i jak się rozwija.
Przy takim szerokim pojmowaniu inteligencji należy pamiętać, że inteligencja nie jest jednowymiarową cechą. Ludzie mogą mieć różne mocne i słabe strony w różnych obszarach inteligencji. Istnieje wiele czynników, które wpływają na inteligencję, w tym genetyka, środowisko i wychowanie.
Badania nad inteligencją wciąż trwają i wiele jeszcze nie wiemy o tej fascynującej zdolności. Oto przykładowe definicje inteligencji, powstałe przed obecną rewolucją technologiczną, związaną z AI:
- Charles Spearman (1904), wprowadził pojęcie „czynnik g” (general intelligence), sugerując, że inteligencja jest pojedynczą zdolnością ogólną, która wpływa na wyniki we wszystkich zadaniach poznawczych.
- Alfred Binet i Théodore Simon (1905) stwierdzili, że inteligencja skupia się na zdolności rozumienia, oceny i wnioskowania. Binet i Simon stworzyli pierwszy test inteligencji, który miał na celu identyfikację dzieci wymagających dodatkowego wsparcia edukacyjnego.
- David Wechsler (1944) zdefiniował inteligencję jako globalną zdolność jednostki do celowego działania, racjonalnego myślenia i efektywnego radzenia sobie z otoczeniem. Jest twórcą popularnych testów inteligencji, takich jak WAIS i WISC.
- Howard Gardner (1983) zaproponował teorię inteligencji wielorakiej, definiując inteligencję jako zdolność do rozwiązywania problemów lub tworzenia produktów, które są cenione w jednym lub więcej kontekstach kulturowych. Zidentyfikował osiem (później dziewięć) rodzajów inteligencji, w tym językową, matematyczno-logiczna, przestrzenną, muzyczną, interpersonalną, intrapersonalną, cielesno-kinestetyczną, przyrodniczą i egzystencjalną.
- Robert Sternberg (1985) opracował teorię trójczynnikową inteligencji, która obejmuje inteligencję analityczną (zdolność do analizy, oceny, oceny i porównywania), kreatywną (zdolność do tworzenia nowych pomysłów) i praktyczną (zdolność do radzenia sobie z codziennymi problemami).
- John Carroll (1993) stworzył teorię trójwarstwową, która sugeruje, że inteligencja ma trzy warstwy: najwęższa obejmuje specyficzne zdolności, średnia warstwa obejmuje szerokie zdolności (takie jak pamięć, uczenie się i percepcja), a najgłębsza warstwa to ogólna inteligencja (czynnik g).
- Daniel Goleman (1995) popularyzował pojęcie inteligencji emocjonalnej, definiując ją jako zdolność do rozpoznawania, rozumienia i zarządzania własnymi emocjami oraz emocjami innych ludzi.
Pięć definicji inteligencji w kontekście AI
Interesując się tematem AI napotkałem kilka szczególnie ciekawych definicji inteligencji. Wybrałem je do udzielenia odpowiedzi na główne pytanie tego artykułu – czy AI jest inteligentne? Są to definicje w mojej ocenie nie tylko trafne, ale pokazujące inteligencję z różnych perspektyw, a przy tym jednocześnie istotnie różniące się od siebie. Właśnie zrozumienie, jak wiele odmiennych definicji inteligencji konkuruje ze sobą, pozwala z odpowiednim dystansem spojrzeć na pytanie o inteligencję AI.
Pięć definicji, które biorę pod uwagę poszukując odpowiedzi na nasze pytanie:
- Jacka Dukaja, który definiuje inteligencję jako zdolność operowania na symbolach. Jest to najbardziej ogólna definicja, jaką spotkałem. Jako najbardziej ogólna, definicja Dukaja zawiera w sobie wszystkie pozostałe definicje przedstawione w artykule.
- Andrzeja Dragana, który definiuje inteligencje jako zdolność do odnajdywania analogii. Nie da się zaprzeczyć, że odnajdywanie analogii pomiędzy różnymi elementami rzeczywistości (np. pomiędzy tym, że jabłka spadają i że ciała niebieskie krążą wokół siebie), wymaga inteligencji.
- Popularna, czyli taka, z którą spotykam się najczęściej i która zdaje się być najczęściej akceptowana. Definicja ta sprowadza się to stwierdzenia, że inteligencja przejawia się w umiejętnościach poznawczych, takich jak umiejętność obserwowania, uczenia się, dostosowywania się do zmieniających się warunków i rozwiązywania problemów.
- Definicja inteligencji rozumianej jako zdolność pozyskiwania wiedzy. Tę definicję spotkałem w środowisku inżynierów oprogramowania badających i rozwijających sztuczne inteligencje. Zwolennicy tej definicji surowo oceniają inteligencję obecnych systemów AI. Jednocześnie ta definicja będzie nam bardzo przydatna to wyjaśnienia dwóch kluczowych etapów funkcjonowania sztucznych inteligencji – treningu i inferencji.
- François Chollet’a, który twierdzi, że inteligencja to skuteczność, z jaką wykorzystujesz informacje z przeszłości, aby poradzić sobie z przyszłością. Uwzględniłem tę definicję w swoim artykule z uwagi na ciekawy i jednocześnie trudny do pokonania dla obecnych AI test inteligencji oparty o definicję Chollet’a. Test ten jest prosty nawet dla dziecka, ale ChatGPT i inne modele nie potrafią sobie z nim za bardzo poradzić.
Definicja Jacka Dukaja - operowanie na symbolach i inteligencja życia.
W jednej z moich notatek z wypowiedziami Jacka Dukaja, genialnego pisarza i futurologa, czytam:
Operacja na symbolach to najszersza definicja inteligencji.
Dukaj opiera się na założeniu, że kluczową cechą inteligentnego działania jest zdolność do manipulowania reprezentacjami – czyli symbolami – w celu rozwiązywania problemów, komunikacji i tworzenia nowych koncepcji. Oto, dlaczego to ma sens:
- Symbol w tym kontekście jest szeroko pojęty i może obejmować słowa, obrazy, znaki matematyczne, gesty, a nawet abstrakcyjne idee, także reprezentowane przez memy. Każdy z tych elementów stanowi reprezentację czegoś większego, prostego lub złożonego, materialnego lub niematerialnego. Operowanie symbolami oznacza zdolność do korzystania z tych reprezentacji w celu myślenia, rozwiązywania problemów lub komunikowania się.
- Umiejętność operowania symbolami jest ściśle związana z myśleniem abstrakcyjnym, czyli zdolnością do myślenia o koncepcjach, które nie są bezpośrednio związane z konkretami doświadczenia sensorycznego. Abstrakcja pozwala na rozumienie i manipulowanie pojęciami, które nie mają fizycznej formy.
- Chyba każda definicja inteligencji wskazuje w mniej lub bardziej bezpośredni sposób na zdolność do adaptacji do nowych sytuacji i rozwiązywania nowych problemów. Dzięki umiejętności operowania symbolami możliwe jest abstrakcyjne myślenie oraz modelowanie różnych scenariuszy i rozwiązań. To z kolei stanowi katalizator procesu rozwiązywania złożonych problemów.
- Kolejny powtarzającym się aspektem inteligencji jest zdolnością do nauki, co oznacza zdolność do zmiany zachowania lub myślenia na podstawie doświadczeń. Nauki dotyczy też jedna z przedstawionych niżej definicji. Operowanie symbolami pozwala na organizację wiedzy, tworzenie i testowanie hipotez, czyli procesy istotne z punktu widzenia nauki.
Podsumowując, umiejętności operowania symbolami jest podstawą abstrakcyjnego myślenia, języka, rozwiązywania problemów i nauki, a to są działania, które uważamy za oznaki inteligentnego zachowania. Zrozumienie inteligencji wymaga zatem zrozumienia zdolności do przetwarzania i manipulowania reprezentacjami.
Wracając do tytułowego pytania – czy zatem sztuczne inteligencje, w szczególności modele językowe, są inteligentne zgodnie z definicją inteligencji jako umiejętności operowania symbolami? Odpowiedź brzmi zdecydowanie tak, ponieważ potrafią analizować, generować i interpretować język naturalny oraz obrazy, które są formami symboli.
Oto, jak to działa na przykładzie ChatGPT:
- ChatGPT potrafi analizować teksty, rozpoznając wzorce i struktury w języku. To umożliwia im zrozumienie znaczenia słów i związków między nimi oraz kontekstu, co jest kluczowe dla operowania symbolami językowymi.
- ChatGPT tworzy nowe teksty na podstawie zrozumianych wzorców i struktur. Generując zdania, paragrafy czy całe artykuły, wykorzystuje znane mu symbole (słowa) i łączy je w sensowną całości, co jest przykładem zaawansowanego operowania symbolami.
- ChatGPT potrafi odpowiadać na pytania, interpretować zapytania użytkowników i dostarczać odpowiedzi w oparciu o informacje zakodowane za pomocą słów. To pokazuje jego zdolność do rozumienia i manipulowania symbolami w sposób, który imituje ludzkie myślenie.
Moim zdaniem nie ma zatem żadnych wątpliwości, że sztuczne inteligencje, takie jak ChatGPT, potrafią operować symbolami w sposób, który spełnia definicję inteligencji Dukaja.

Fascynujące konsekwencje definicji Dukaja
Zanim rozstanę się z przemyśleniami Dukaja i przejdę do kolejnej definicji, chcę podzielić się z Tobą dwoma fascynującymi przemyśleniami tego niesamowicie mądrego człowieka.
Pierwsze przemyślenie, to wizja, która również i mi chodziła po głowie, a której potwierdzenie znalazłem w słowach Dukaja.
W jednym z wywiadów Dukaj stwierdził, że przykładem umiejętności operowania na symbolach jest kod DNA. Logicznym jest zatem wniosek, że życie samo w sobie jest inteligentne i do ekspresji tej inteligencji nie potrzebuje ani mózgu, ani nawet układu nerwowego.
Cytując Dukaja:
Do powstania nowej informacji czy wiedzy, nie jest potrzebny agent samoświadomy. W naszym przypadku był ten agent – homo sapiens, który wykształcił cywilizację technologiczną. Nie jest to jednak konieczne. Mózg Boltzmanna jest ekstremalnym przykładem – teoretycznie może powstać mózg inteligentny.
Zdaniem Dukaja, z którym ponownie się zgadzam, DNA działa w sposób inteligentny, zawiera w sobie pewien niezrozumiany do dziś przez ludzkość pierwiastek inteligencji. Jest to pierwiastek niezrozumiały, ponieważ do dziś nie mamy pewności, w jaki sposób DNA powstało i skąd ‘wie’, jak operować aminokwasami (które występują tu w roli symboli), aby kodować informacje dotyczące produkcji odpowiednich białek.
To nie mózg, to nie choćby najprostszy układ nerwowy, ale samo życie na najniższym, cząsteczkowym poziomie, operuje sekwencjami nukleotydów (A, T, C, G) jako symbolami, które kodują informacje genetyczne. Procesy replikacji, transkrypcji i translacji DNA, które przekształcają kod genetyczny na RNA i białka, oraz zdolność DNA do mutacji i ewolucji, pokazują, jak życie wykorzystuje abstrakcyjne symbole do przechowywania, przetwarzania i przekazywania informacji.
Jestem nieustannie zafascynowany tą koncepcją i pod wpływem tej fascynacji publikuję takie posty w sieciach społecznościowych:
My tu gadu gadu o LLMach, a inteligentna natura tworzy cząsteczkowe silniki ze sprzęgłami obrotowymi, wałami napędowymi i łożyskami, które pracują z prędkością 20 tysięcy obrotów na minutę.
— Maciej Michalewski — e/acc (@Maciej_M) August 15, 2024
Wydaje nam się, że jesteśmy tak zaawansowani, a w rzeczywistości rozumiemy i potrafimy… https://t.co/2wU4f9xUG2
Inteligencja już na etapie cząsteczek chemicznych może być dla niektórych trudna do zaakceptowania. Skoro ktoś wciąż kwestionuje inteligencję modeli językowych takich jak ChatGPT, to tym bardziej nie zaakceptuje inteligencji DNA, czy ogólnie materii.
Ja jednak zgadzam się z definicją Dukaja. Uważam, że życie powstało właśnie dzięki inteligencji zakodowanej gdzieś głęboko w strukturze rzeczywistości. Nieprawdopodobnie skomplikowane i niezrozumiane przez nas życie, którego wciąż nie potrafimy odtworzyć, jest owocem jakiejś inteligencji.
Jakiejś inteligencji? Jakieś innej niż nasza? Czy mogą istnieć inne inteligencje? By odpowiedzieć na te pytania, przejdziemy do kolejnego fascynującego przemyślenia Jacka Dukaja.
Oto kolejny cytat Dukaja zapisany w moich notatkach:
Jakie jest prawdopodobieństwo, że nasze rozumienie inteligencji, jest wzorcowym dla inteligencji w ogóle? Wyobraźmy sobie przestrzeń fazową, w której mamy tyle wymiarów, ile jest możliwych zmiennych dla zbudowania inteligencji w ogóle i w tej przestrzeni fazowej mamy jeden punkcik i to jest inteligencja taka, jaką posiada homo sapiens. Jakie jest prawdopodobieństwo, że to jest optymalna forma inteligencji, że żadna inna jej nie pobije? Jeżeli po osiągnięciu technologicznej osobliwości pozwolimy, aby nasza sztuczna inteligencja budowała sobie kolejne, lepsze jej formy, to logicznie poruszając się po tej przestrzeni fazowej będzie oddalać się w niej od inteligencji homo sapiens ku coraz dziwniejszym obcym formom inteligencji. W przeciwnym wypadku musielibyśmy uznać, że wszechświat jest antropiczny. Czyli że powstał w takiej kombinacji założeń, praw fizyki, cząstek elementarnych, prędkości światła i tak dalej, po to tylko, żeby w niej wyewoluowana ludzka inteligencja była optymalna. Czyli to jest rodzaj jakby wiary kopernikańskiej. Jeżeli w nią nie wierzymy, to logiczną konsekwencją jest to, że ludzka inteligencja jest przypadkową wersją inteligencji, która mieści się na obrzeżach przestrzeni fazowej, a optymalna jest w gdzieś w środku.
Innymi słowy, zdaniem Dukaja, z którym ponownie trudno mi się nie zgodzić, jeśli odrzucamy wszechświat antropiczny (w skrócie taki, który powstał po to, aby mógł powstać człowiek), to rodzajów inteligencji może być nieskończenie wiele, a inteligencja ludzka najprawdopodobniej nie jest najbardziej optymalna. Inteligencja, także sztuczna inteligencja, może zatem rozwinąć się do tej bardziej optymalnej, a zatem silniejszej wersji inteligencji i tym samym uzyskać przewagę nad inteligencją ludzką.
W opisywanej przez Dukaja przestrzeni fazowej może istnieć wiele innych inteligencji, słabszych, silniejszych, odmiennych i niezrozumiałych. Być może właśnie taka niezrozumiała dla nas inteligencja stworzyła życie potrafiąc operować symbolami na poziomie materii podstawowej, takiej jak cząsteczki chemiczne, a może nawet subatomowe. Fascynujące!
Definicja Andrzeja Dragana
Andrzej Dragan, światowej klasy badacz fizyki kwantowej, który jednocześnie żywo interesuje się sztuczną inteligencją, twierdzi, że inteligencja to umiejętność budowania porównań, dostrzegania wzorców i analogii. Dragan zilustrował to przykładem Isaaca Newtona, który uznany jest za jednego z najwybitniejszych naukowców w historii właśnie dlatego, że potrafił zbudować analogię pomiędzy prawami rządzącymi spadającym jabłkiem a „pikselami” – cytując Dragana – na niebie, czyli gwiazdami.
Dragan przedstawia różnorodne przykłady na to, że ChatGPT potrafi zastosować prawa fizyki do nowych sytuacji, których wcześniej nie widział (tzn. nie miał ich w swoich danych treningowych). Również ja wymyśliłem taki przykład, celowo oderwany od rzeczywistości, aby upewnić się, że ChatGPT nigdy go wcześniej nie widział. Oto przykład i odpowiedź ChatGPT:


ChatGPT prawidłowo porównał sytuację opisaną w pytaniu ze znanymi sobie prawami fizyki.
Po pierwsze przeanalizował sytuację i ocenił elementy istotne z punktu widzenia pytania, tj. wysokość słonecznika, stabilność łodygi i wagę dziecka. Po drugie porównał właściwości fizyczne, tj. wytrzymałość słonecznika z siłą nacisku wywieraną przez stopę dziecka.
ChatGPT prawidłowo wnioskuje, że słonecznik, choć roślina o grubej łodydze, nie jest wystarczająco stabilny, aby utrzymać ciężar dziecka. Udziela prawidłowej odpowiedzi biorąc pod uwagę wszystkie powyższe informacje.
To prosty przykład, który dowodzi, że modele te potrafią – czasem lepiej, czasem gorzej – dokonywać porównań, stosować odpowiednie modele rzeczywistości, w tym przypadku model praw fizyki, do odpowiednich i nowych dla siebie sytuacji. Tym samym spełniona jest definicja inteligencji profesora Dragana.
Definicja popularna - umiejętności poznawcze
Oprócz szczególnych definicji inteligencji, do których zaliczam między innymi definicję Dukaja i Dragana, istnieją definicje powszechnie spotykane, którymi sam posługuję się, choćby podczas szkoleń wprowadzających w tematykę AI.
Przykłady tych popularnych definicji przytoczyłem wcześniej, przedstawiając historię nauki o inteligencji. Z grubsza, definicje popularne ujmują inteligencję jako zestaw umiejętności poznawczych, takich jak umiejętność postrzegania, uczenia się, rozwiązywania problemów, oceniania, wnioskowania.
Podany wcześniej przykład rozmowy z ChatGPT na temat słonecznika i dziecka jest dowodem spełnienia tej popularnej definicji, albowiem ChatGPT udzielił odpowiedzi na moje pytanie korzystających z tych poznawczych umiejętności. ChatGPT musiał najpierw nauczyć się praw fizyki, ocenił nową sytuację, prawidłowo wnioskował o tym, jakie prawa fizyki do tej sytuacji zastosować i jak te prawa w tej konkretnej sytuacji zadziałają. W konsekwencji ChatGPT prawidłowo rozwiązał problem w swojej odpowiedzi.
Dowodem robiącym znacznie większe wrażenie, który dosadnie pokazuje także umiejętność postrzegania, będzie prezentacja multimodalnych możliwości ChatGPT 4o. Weźmy na przykład to krótkie video:
Definiowanie przez zdolność zdobywania wiedzy - tu zaczynają się problemy z inteligencją AI
Śledząc to, co mówi się o inteligencji wśród inżynierów uczenia maszynowego, spotkałem się kilkukrotnie z definicją, którą dzisiejsze AI spełnia tylko w niewielkim zakresie. Definicja ta sprowadza się do stwierdzenia, że inteligencja to zdolność pozyskiwania nowej wiedzy.
Ta definicja przyjmuje różne formy:
- Rozumowanie to proces pozyskiwania wiedzy. Inteligencja to efektywność tego procesu.
- Inteligencja to umiejętność zdobywania wiedzy.
- Inteligencja to umiejętność tworzenia modeli rzeczywistości.
- Inteligencja to umiejętność poszerzania horyzontów na podstawie kilku przykładów, uwzględniając swoją wcześniejszą wiedzę i doświadczenie.
- Inteligencja to zdolność do wypełniania luk w wiedzy bez oszukiwania (tj. bez wcześniejszego dostępu tej wiedzy w danych treningowych,) i bez stosowania statystycznych lub percepcyjnych skrótów.
Wspólnym mianownikiem powyższych definicji jest umiejętność uczenia się, umiejętność samodzielnego zdobywania nowej wiedzy w oparciu o dotychczasową wiedzę i dotychczasowe doświadczenia, ale bez bezpośredniego pozyskiwania tej nowej wiedzy ze źródeł zewnętrznych.
Modele językowe, takie jak ChatGPT, maja olbrzymi zasób wiedzy, ale czy potrafią tę wiedzę wykorzystać by samodzielnie zdobywać nową wiedzę?
Zanim odpowiem na to pytanie, warto przyjrzeć się samemu procesowi zdobywania wiedzy przez AI. Proces ten przedstawię za pomocą interakcji użytkownika z ChatGPT.
Czy AI uczy się czegoś podczas rozmowy z użytkownikiem?
Jeśli w oknie dialogowym ChatGPT wpiszemy jakąś nieznaną mu informację, na przykład “Maciej Michalewski lubi mango i awokado” to wiedza ChatGPT nie powiększy się. To, co ChatGPT zrobi z tą informacją, to wykorzysta ją jedynie do udzielenia odpowiedzi.

Jeśli w dowolnym innym momencie rozpocznę nową rozmowę z ChatGPT i zapytam o to, jakie owoce lubi najbardziej Maciej Michalewski, to ChatGPT nie będzie znał odpowiedzi na to pytanie i będzie mógł co najwyżej próbować zgadywać.

Ten prosty przykład dowodzi, że ChatGPT nie zdobywa nowej wiedzy podczas rozmowy z użytkownikami, nie zdobywa, bo nawet nie zapamiętuje podanych w prompcie (zapytaniu) informacji.
Reasumując, sztuczne inteligencje nie zapamiętują w swojej sieci neuronowej informacji, którą wprowadzamy za pomocą promptów (zapytań), one jedynie te informacje procesują w ramach prowadzonej rozmowy.
Pozyskiwanie nowej wiedzy przez rozumowanie.
Nawet jednak, gdyby ChatGPT rzeczywiście trwale zapamiętywał podawane przez użytkowników informacje, na przykład w jakieś pamięci podręcznej, to nie oznaczałoby, że te informacje zrozumiał.
Czym innym, niż zapamiętywanie faktów, jest pozyskiwanie nowej wiedzy przez rozumienie tych faktów. Rozumienie, czyli dostrzeganie w informacjach relacji, dzięki którym tworzymy wzorce myślowe. Te wzorce myślowe wykorzystujemy później do rozwiązywania nowych problemów.
Przykład – dziecko dostrzega, że jego działania wpływają na otoczenie (relacja między działaniem a efektem tych działań). Podejmując kolejne, także nowe działania, dziecko coraz lepiej przewiduje ich konsekwencje. Im więcej razy dziecko rozleje kubek z mlekiem, co spotka się z uwagą rodziców, tym w przyszłości ostrożniej będzie postępować nie tylko z kubkiem z mlekiem, ale także z innymi naczyniami.
Oto przykład z ChatGPT, który zobrazuje różnicę pomiędzy zdobywaniem wiedzy poprzez zapamiętywanie i rozumowanie. ChatGPT wie, że ziemia krąży wokół słońca, ponieważ w danych uczących napotkał na wiele informacji wprost opisujących i potwierdzających ten fakt. Nie musiał zatem rozumować, aby tę wiedzę pozyskać. Gdyby jednak ChatGPT sam potrafił ten fakt odkryć w taki sposób, jak zrobił to Mikołaj Kopernik, czyli na podstawie obserwacji i wyliczeń, to mielibyśmy do czynienia z pozyskaniem nowej wiedzy w wyniku pewnego procesu myślowego, czyli w wyniku rozumowania.
W punkcie “Czy AI uczy się czegoś podczas rozmowy z użytkownikiem?” wskazałem, że ChatGPT otrzymując od nas nowe informacje podczas rozmowy, nie zapamiętuje tych informacji, a jedynie je przetwarza, by udzielić odpowiedzi. Skoro ChatGPT nie zapamiętuje informacji, to nie pozyskuje nowej wiedzy w oparciu o zapamiętywanie. Skoro zaś nie zapamiętuje informacji, to tym bardziej buduje wiedzy w oparciu rozumowanie, ponieważ nie zapamiętał informacji, które mogą być przedmiotem jego rozumowania. Skoro tak, to kiedy ChatGPT zdobywa wiedzę?
Czy ChatGPT pozyskuje nową wiedzę?
Pozyskuje! Przecież gdyby nie pozyskiwał, to by nie potrafił tego, co potrafi. Bez wiedzy o świecie nie potrafiłby odpowiadać na wszystkie nasze pytania, ogólne, czy bardzo szczegółowe, z dowolnych obszarów wiedzy, z dowolnych specjalizacji.
Jak zatem sztuczne inteligencje pozyskują wiedzę? Kiedy ją pozyskują? Czy pozyskują zapamiętując, czy też w wyniku rozumowania? A może jedną i drugą metodą?
Aby odpowiedzieć na to pytanie, musimy wyraźnie rozróżnić dwa etapy funkcjonowania sztucznych inteligencji:
- Trening
- Inferencja (~wnioskowanie)
Trening sztucznej inteligencji
Trening to po prostu uczenie modelu, aby stał się inteligentny. To trochę jak z rozwojem dziecka (w dużym uproszczeniu), które po urodzeniu inteligencji ma co najwyżej zalążki. Zalążki te, wraz z upływem czasu i nauki, rozwijają się, by z czasem pokazać pełen potencjał ludzkiej inteligencji. Taki ChatGPT przed rozpoczęciem treningu nie ma nawet zalążka inteligencji i na nasze pytania nie odpowie w żaden sensowny sposób (będzie to co najwyżej losowy ciąg znaków).
Trenowanie trwa, kosztuje, wymaga fabryk i energii
Trenowanie sztucznych inteligencji to proces, który przy tak dużych modelach jak ten z ChatGPT:
- trwa miesiącami,
- odbywa się w fabrykach sztucznych inteligencji (wyobraź sobie halę wielkości supermarketu wypełnioną setkami tysięcy procesorów zamkniętych w takich szafach, jak na poniższym zdjęciu)
- wykorzystuje duże zasoby energii
- kosztuje miliony dolarów

Trenowanie sztucznych sieci neuronowych
Sztuczne inteligencje, takie jak ChatGPT, zbudowane są bazie sztucznych sieci neuronowych. Te sieci w dużym uproszczeniu przypominają sieci neuronowe mózgu. Tak jak w mózgu, sztuczne neurony połączone są ze sobą w strukturze sieci (jeden neuron może być połączony z wieloma innymi neuronami). Każde połączenie pomiędzy sztucznymi neuronami to w praktyce pewna wartość liczbowa. Właśnie ta wartość liczbowa nazywana jest parametrem i tych parametrów, czyli połączeń pomiędzy sztucznymi neuronami, jest w GPT 4 około 1.8 biliona. To właśnie nadanie pewnej ściśle określonej wartości każdemu z tych niecałych 2 bilionów parametrów, jest trenowaniem. Im lepiej ustawione parametry sieci neuronowej, tym bardziej inteligentna jest ta sieć.
Sam trening sztucznych sieci neuronowych polega na dostarczeniu do tej sieci gigantycznego zbioru danych (wyobraź sobie duży kawał Internetu). Te dane są wykorzystywane do ustawienia parametrów sieci neuronowej w taki sposób, aby – w dużym uproszczeniu – sieć zrozumiała te dane, wydobyła zapisaną w nich wiedzę i nabyła umiejętność posługiwania tą wiedzą. Ponownie upraszczając, wprowadzając do tej sieci neuronowej dane treningowe zawierające tekst, sieć uczy się posługiwać językiem i jednocześnie nabywa wiedzę zapisaną w tym tekście.
Jeśli chcesz zobaczyć, jak w praktyce zbudowana jest sztuczna inteligencja, a konkretnie sztuczna sieć neuronowa, w której inteligencja się pojawia, to polecam ten dwuodcinkowy (łącznie kilkadziesiąt minut) film, który na prostych przykładach i wykorzystując łatwe do zrozumienia animacje, wyjaśnia czym są sztuczne sieci neuronowe, w jaki sposób potrafią przejawiać inteligencję i jak są tej inteligencji uczone:
Gdzie model zapamiętuje informacje?
Warto pamiętać i jest to niezwykle ciekawe, że w modelach sztucznej inteligencji nie ma czegoś takiego, jak miejsce na zapisywanie faktów. Sztuczna inteligencja nie ma w sobie jakiegoś pliku z tekstem encyklopedii, nie ma osobnej pamięci, z której pobiera potrzebne informacje. To, że sieć sztucznych neuronów nie ma bazy danych z zapisanymi informacjami o świecie, a mimo to pamięta wszystkie fakty, o których dowiedziała się podczas treningu, jest niezwykłą cechą sieci sztucznych neuronów.
Jak wspomniałem, podczas trenowania, parametry modelu, czyli tej sieci neuronów, przyjmują pewne wartości liczbowe. To właśnie w relacjach między tymi wartościami zapisana jest cała wiedza modelu. Świetnie to przedstawia wspomniany wyżej materiał wideo.
Trenowanie AI to kompresja wiedzy
Biliony parametrów ChatGPT, to ciąg liczb. Te liczby możemy zapisać w zwykłym notatniku, np. w formacie txt. Taki plik możemy trzymać na dysku i w ten sposób przechowywać zakodowany w nim ogromny zbiór wiedzy o ludzkości i świecie. W uproszczeniu plik przechowuje wiedzę i inteligencję. Do uruchomienia tej inteligencji potrzebne jest jednak przeniesienie zapisanych w pliku liczb na infrastrukturę sprzętową i programistyczną, dzięki której nasze AI “ożyje”.
Jak wspomniałem wcześniej, model trenowany jest na dużym kawałku Internetu. Na tekstach, na zdjęciach, na filmach, na obrazach. Gdybyśmy te wszystkie multimedia treningowe chcieli zapisać na dysku, to potrzebowalibyśmy dyski setki razy większe, niż dysk potrzebny do zapisania naszego pliku txt z parametrami. Zatem to, co dzieje się podczas treningu, to kompresowanie wiedzy zapisanej w tych multimediach treningowych. Kompresowanie filmów, muzyki, tekstów, czyli form zrozumiałych dla człowieka, do formy kompletnie dla nas niezrozumiałej, czyli ciągu 1,8 biliona liczb. Liczb, z których każda z osobna nic nie znaczy, ale wszystkie razem, zapisane w strukturze sieci neuronowej, tworzą inteligencję. Podobnie zresztą nic nie znaczy pojedyncza komórka neuronowa mózgu oddzielona od swojej sieci, ale cały mózg jest inteligentny.
Ten fakt kompresji danych podczas treningu podkreślany był wielokrotnie przez profesora Dragana w jego licznych rozmowach o sztucznej inteligencji. Dragan przytaczał przy tym konkurs Hutter Prize, na stworzenie najbardziej skutecznego algorytmu kompresji danych. Nagroda wynosi 5000 euro za każdy procent poprawy kompresji, z całkowitą pulą nagród wynoszącą 500 000 euro
Rozumowanie podczas trenowania
Wracając jednak do istoty sprawy – w odróżnieniu do etapu inferencji (o którym za chwilę), na etapie trenowania pojawia się rozumowanie. Przypomnę tu jedną z podanych wyżej definicji – rozumowanie to proces pozyskiwania wiedzy.
Podczas treningu model przyjmuje dane treningowe i odczytuje z tych danych nie tylko fakty, ****ale także wzorce, relacje i reguły rządzące tymi danymi (rozumienie faktów). Fakty ich zrozumienie stanowią nową wiedzę modelu i tę wiedzę model zapamiętuje poprzez nadanie swoim parametrom określonych wartości liczbowych.
Dane treningowe, które pochodzą z Internetu, zawierają przede wszystkim obraz rzeczywistości (np. encyklopedie, prace naukowe, podręczniki, wiadomości i dyskusje na bieżące tematy). W związku z powyższym w parametrach modelu zapisany zostaje wzór reguł rządzących rzeczywistością, zaczynając od teorii fizycznych, a kończąc na psychologicznych. W parametrach modelu zapisane są także wzorce ludzkiego myślenia, które przenikają do modelu z tych danych.
Wzorce ludzkiego myślenia? Tak. Oprócz podręczników, encyklopedii, czy badań naukowych, Internet zawiera przede wszystkim wszelkie formy komunikacji międzyludzkiej. Ta komunikacja zapisana jest w wiadomościach email, historii czatów, dyskusjach na forach i social mediach, czy dialogach filmów i książek. Wszystko to różnorodne formy zapisu ludzkich myśli i z tych zapisów sieć neuronowa wyciąga wzorce naszego myślenia, nawet takie, których my nie dostrzegamy.
Skąd wiemy, że model rzeczywiście rozumuje?
Skąd wiemy, że model rzeczywiście to wszystko zrobił, że nauczył się faktów, że zrozumiał reguły rządzące światem, że wie jak myślą ludzie?
Wiemy to stąd, że ChatGPT (i inne modele językowe) sensownie rozmawia z nami na wszystkie tematy, odpowiada tak, jak człowiek (przeszedł test Turinga), potrafi odczytywać emocje, a nawet potrafi te emocje symulować (używam słowa “symulować” ale nie wiem, gdzie kończy się symulowanie emocji, a zaczyna ich przeżywanie).
Co więcej, AI potrafią rozwiązywać nowe problemy stosując poznane wzorce i reguły rządzące światem, co można samodzielnie sprawdzić tworząc takie przykłady, jak ten zaprezentowany wcześniej przykład dziecka i słonecznika.
Trening modelu podstawowego i fine tuning
A propos sprawnej komunikacji ChatGPT z człowiekiem wspomnę, że ta bardzo dobra komunikacja możliwa jest dzięki dwufazowemu treningowi modelu. W pierwszej fazie treningu model uczy się wzorców i relacji z ogromnych zbiorów danych, tworząc tak zwany model podstawowy (ang. foundation model). Następnie model jest dostrajany w fazie tak zwanego fine tuning’u na dodatkowych danych do konkretnych zadań komunikacyjnych, np. do komunikacji w języku naturalnym na niemal dowolny temat, jak ChatGPT, lub do komunikacji w zakresie konkretnej specjalizacji, np. obsługi klienta czy udzielania porad medycznych.
Konceptualne zrozumienie
Pisząc o rozumieniu treści zawartych w danych treningowych napisałem, że to rozumienie wiąże się z uchwyceniem ukrytych w tych danych relacji między faktami, reguł rządzących rzeczywistością i wzorców myślowych. Wszystko to związane jest konceptualnym zrozumieniem.
Konceptualne zrozumienie składa się z trzech elementów:
- Abstrakcyjność Model rozumie na poziomie idei i pojęć, a nie tylko konkretnych faktów czy procedur. Przykład: Podczas treningu ChatGPT nauczył się rozpoznawać różne gatunki psów. Model nie zapamiętał jedynie konkretnych obrazów psów, ale stworzył abstrakcyjne pojęcie psa, identyfikując cechy takie jak kształt uszu, rodzaj sierści, czy proporcje ciała. Dzięki temu, gdy zobaczy nowego psa, którego nigdy wcześniej nie widział, będzie mógł go rozpoznać jako psa na podstawie tych abstrakcyjnych cech.
- Przenikanie istoty Pojmowanie fundamentalnych zasad i powiązań, które leżą u podstaw zagadnienia. Przykład Model językowy wytrenowany jest na ogromnej ilości tekstów. Dzięki model temu potrafi przeniknąć istotę gramatyki i składni języka (nawet jeśli w danych treningowych nie było podręczników z regułami językowymi). Model nie tylko zapamiętuje frazy, ale rozumie fundamentalne zasady, które rządzą konstrukcją zdań. Dzięki temu może generować poprawne gramatycznie zdania nawet w kontekstach, których wcześniej nie widział, rozumiejąc jak poszczególne części mowy wiążą się ze sobą.
- Uogólnienie Trening obejmuje nie tylko zapamiętywanie danych treningowych, ale także ich uogólnianie. Model uczy się stosować odkryte wzorce i relacje do nowych, nieznanych mu danych. Przykład Model predykcji cen nieruchomości uczy się na podstawie historycznych danych dotyczących cen, lokalizacji, wielkości nieruchomości i innych zmiennych. Po treningu model jest w stanie uogólnić te informacje i przewidywać ceny nieruchomości w nowych lokalizacjach, których wcześniej nie widział. Robi to, identyfikując wzorce i relacje między różnymi zmiennymi (np. bliskość szkół, przystanków komunikacji publicznej) i stosując je do nowych danych.
Podsumowując, konceptualne zrozumienie, do którego dochodzi podczas trenowania modeli, jest zdobywaniem przez AI wiedzy za pomocą rozumowania, ponieważ wskazuje, że model zrozumiał coś fundamentalnego na temat danych, poza zwykłym ich zapamiętaniem.
Zdobywanie wiedzy podczas treningu - podsumowanie
Podsumowując, wykazałem powyżej, że podczas etapu trenowania sztuczna inteligencja faktycznie zdobywa wiedzę. W konsekwencji należy uznać, że etap trenowania spełnia definicję inteligencji rozumianą, jako zdolność do zdobywania nowej wiedzy.
Inferencja - drugi etap działania sztucznej inteligencji
Inferencja (z ang. inference) to drugi, po trenowaniu, etap działania sztucznych inteligencji. Jest to etap, w której wytrenowany model realizuje zadania, dla których został stworzony. W przypadku ChatGPT inferencja to po prostu otrzymywanie pytań (promptów) od użytkowników i udzielanie odpowiedzi.
Wyjaśnijmy najpierw samo pojęcie – inferencja to proces myślowy, w którym na podstawie uznanych za prawdziwe zdań dochodzi się do stwierdzenia nowego twierdzenia. Termin ten wywodzi się z łaciny i jest używany w różnych dziedzinach, takich jak logika, matematyka, językoznawstwo oraz informatyka.
Inferencja nie obejmuje dalszego uczenia się. Podczas etapu inferencji AI stosuje to, czego nauczył się podczas etapu treningu. Podczas inferencji nie ma uczenia się i nie ma zdobywania nowej wiedzy. Podczas inferencji parametry modelu nie są aktualizowane. Model po prostu stosuje wyuczone wzorce do nowych danych wejściowych (promptów) w celu wygenerowania danych wyjściowych (odpowiedzi na prompty).
Przypomina to sytuację, w której osoba wykorzystuje swoją istniejącą wiedzę do rozwiązania problemu, nie ucząc się przy tym niczego nowego. Jest to wykonywanie znanej strategii, a nie odkrywanie nowej.
Przykład prezentujący różnicę pomiędzy inferencją i trenowaniem - student w trakcie nauki i egzaminu
Oto przykład, który obrazuje różnice pomiędzy trenowaniem a inferencją.
Wyobraźmy sobie studenta uczącego się rozwiązywać nowe problemy matematyczne. W trakcie nauki napotyka te problemy i poszukuje rozwiązań za pomocą znanych mu zasad i technik. Rozumowaniem odnajduje nowe reguły, dzięki którym rozwiązuje te nowe problemy i zdobywa nową wiedzę. Ta faza obejmuje próby i błędy, informacje zwrotne i ciągłe doskonalenie, podobnie jak model uczenia maszynowego aktualizuje swoje parametry podczas treningu. Jest to zatem etap treningu.
Gdy ten sam uczeń przystępuje do egzaminu, stosuje wiedzę i techniki, których się nauczył, do rozwiązywania nowych problemów. Nie uczy się podczas egzaminu, ale wykorzystują swoją istniejącą wiedzę do odpowiadania na pytania.
Podobnie jest w przypadku sztucznej inteligencji. Na etapie inferencji, model stosuje wzorce i reguły, których nauczył się podczas szkolenia do nowych danych bez dalszych modyfikacji swoich parametrów (bez uczenia się).
Trenowanie i inferencja - podsumowanie
Podsumowując, trenowanie modelu to dynamiczny proces, który obejmuje rozumowanie i zdobywanie wiedzy. Podczas treningu algorytm uczenia maszynowego dostosowuje parametry modelu na podstawie danych treningowych. W przeciwieństwie do tego, inferencja jest statycznym zastosowaniem zdobytej wiedzy do nowych danych, bez możliwości dalszego uczenia się.
Jak to wszystko ma się do naszej definicji inteligencji rozumianej jako zdolność do pozyskiwania nowej wiedzy?
Ma się tak, że zgodnie z tą definicją, AI przejawia inteligencje wyłącznie w trakcie treningu, bo to tylko w tej fazie zdobywa faktycznie nową wiedzę.
Wielkim wyzwaniem technologicznym jest stworzenie takiego modelu, który będzie zdolny aktualizować swoje parametry także podczas etapu inferencji. Model taki byłby dużym krokiem w kierunku stworzenia AGI, czyli generalnej sztucznej inteligencji, co jest obecnie celem największych graczy w obszarze AI.
Definicja François Chollet’a i test ARC
François Chollet to inżynier oprogramowania specjalizujący się w sztucznej inteligencji i od 2012 pracujący w Google. François opublikował w 2019 roku pracę naukową pod tytułem On the Measure of Intelligence. Zgodnie z tą pracą, François definiuje inteligencję jako zdolność do przystosowania się do stale zmieniającego się środowiska i odpowiedniego reagowania w nowych sytuacjach. Specyfikę tej definicji i trudność jej spełnienia przez AI, poznamy lepiej, omawiając test ARC, stworzony właśnie na potrzeby tej definicji.
Intelligence is the efficiency with which you operationalize past information in order to deal with the future.
— François Chollet (@fchollet) August 14, 2024
You can interpret it as a conversion ratio, and this ratio can be formally expressed using algorithmic information theory. pic.twitter.com/CvF71Bgk2A

Test ARC
By badać, w jakim stopniu AI spełniają powyższą definicję i jak zbliża się do poziomu AGI (artificial general intelligence), powstał test ARC (Abstraction and Reasoning Corpus).
Aby wyjaśnić przydatność testu ARC przypomnę, że obecne sztuczne inteligencje nie potrafią radzić sobie z nowymi problemami spoza ich danych treningowych, mimo szerokiego treningu na dużych zbiorach danych. Jest to problem, który spowalnia postęp w kierunku AGI.
Co to znaczy “nowymi problemami spoza ich danych treningowych”? Przypomnij sobie mój przykład ze słonecznikiem i dzieckiem, . To był przykład, którego ChatGPT nigdy wcześniej nie widział, ale poradził sobie z nim. Sęk w tym, że problem ten dotyczył interakcji przedmiotów w świecie fizycznym, który modelowi jest dobrze znany. Jak wspominałem omawiając ten przykład, ChatGPT podczas etapu treningu zrozumiał, jakimi prawami rządzi się rzeczywistości i po prostu zastosował te prawa do rozwiązania nowego problemu. Ten nowy problem (słonecznik i dziecko) był jednak problemem osadzonym w świecie dobrze znanym modelowi. Test ARC działa inaczej.
Test ARC podaje modelom zadania, których reguł rozwiązywania nigdy wcześniej nie widział. To tak jakby ChatGPT miałby rozwiązać naszą zagadkę ze słonecznikiem i dzieckiem w innej rzeczywistości, w której działają zupełnie odmienne i kompletnie nieznane mu prawami fizyki. ChatGPT nie poradziłby sobie z takim zadaniem.
Zobaczmy jak działa test ARC.
Na czym polegają zadania i skąd bierze się trudność testu ARC?
Na wstępie warto podkreślić, że do rozwiązania zadań testu ARC wystarczy podstawowa wiedza, tzn. taka, jaką naturalnie nabywają małe dzieci. Nie ma konieczności posiadania wiedzy specjalistycznej. ARC jest testem zaprojektowanym w taki sposób, aby mógł wziąć w nim udział każdy, niezależnie od pochodzenia, w tym Marsjanin, człowiek lub maszyna.
Każde zadanie składa się z siatek o rozmiarach od minimum 1×1 do maksimum 30×30.
Komórki w siatce są wypełnione liczbami od 0 do 9, z których każda jest reprezentowana przez inny kolor, w sumie dziesięć różnych kolorów.
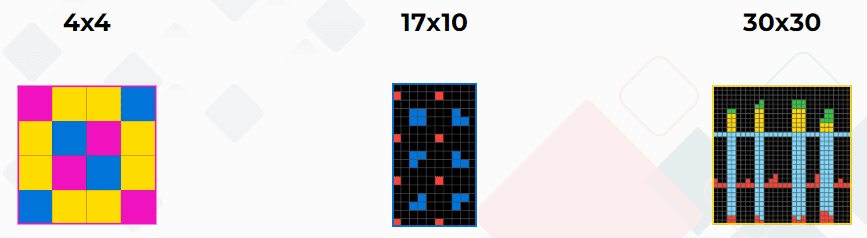
Uczestnicy testu otrzymują zestaw demonstracyjnych siatek. Służą one jako przykłady, na podstawie których należy utworzyć kolejną siatkę podczas testu. Zadanie polega na określeniu rozmiaru siatki i wypełnieniu każdej komórki siatki odpowiednim kolorem lub liczbą. Konstrukcja siatki jest uznawana za prawidłową tylko wtedy, gdy zarówno rozmiar siatki, jak i kolor każdej komórki dokładnie odpowiadają oczekiwanej odpowiedzi.

W powyższym przykładzie ukrytą regułą, którą przeciętny człowiek bez problemu zauważy i Ty z pewnością również, jest wypełnienie kolorem żółtym wszystkich czarnych kwadratów, które na swoich wszystkich bokach mają sąsiadujące kwadraty zielone.
Nawet jeśli tak oczywiste dla nas testowe przykłady podamy modelowi w trakcie treningu, skuteczność rozwiązania w na etapie inferencji wynosi zaledwie 34%, co jest wynikiem znacznie poniżej ludzkich możliwości (84%).
Dlaczego zatem te zadania są tak trudne do rozwiązania dla obecnych sztucznych inteligencji?
Większość naszych zadań, które wykonujemy za pomocą AI, realizowana jest dzięki dużej ilości danych treningowych i dzięki rozpoznawaniu wzorców z tych danych (konceptualne rozumienie). ChatGPT świetnie odpisuje nam na nasze pytania, bo doskonale pisze. ChatGPT świetnie radzi sobie z zagadką ze słonecznikiem i dzieckiem, bo doskonale zna prawa fizyczne z danych treningowych i potrafi odpowiednie prawa zastosować do odpowiednich problemów.
Inaczej jest w przypadku zadań testu ARC. Tu zadania dotyczą unikalnych i skomplikowanych wzorców, których model nigdy nie widział, lub widział zbyt mało, w swoich danych treningowych.
Test co prawda dostarcza przykłady dla każdego zadania, ale przykładów jest dosłownie kilka i okazuje się, że jest to dalece niewystarczająca liczba, żeby model zdołał wykryć w tych przykładach rządzące nimi reguły. Nastolatek potrafi te reguły wychwycić szybko, ChatGPT w ogóle albo z dużą trudnością. Okazuje się, że nie da się wytrenować modelu do osiągnięcia wyniku zbliżonego, do wyniku przeciętnego, niewyszkolonego w tego typu zadaniach człowieka. Innymi słowy, modele działają dobrze, gdy mają duże zbiory danych do trenowania, ale ARC stawia wyzwanie modelom, aby zrozumiały i uogólniły zasady na podstawie małej liczby przykładów. Z tym zadaniem współczesne AI nie radzą sobie.
Test ARC został zatem zaprojektowany w taki sposób, aby mierzył poziom inteligencji rozumianej jako umiejętność odnajdywania w nielicznych przykładach nowych reguł niezbędnych do rozwiązywania nowych problemów.
Odpowiedź na nasze pytanie jest niebinarne
Wspomniany wyżej wynik 34% w teście ARC, który z pewnością systematycznie będzie się podnosił, podpowiada nam jeszcze jeden ważny aspekt dyskusji o inteligencji. Inteligencja nie jest pojęciem binarnym.
To nie jest tak, że albo jest się inteligentnym, albo się nie jest. Dotyczy to zarówno ludzi jak i komputerów.
W przypadku ludzi poziom inteligencji mierzy się współczynnikiem IQ. Pomiar ten wykonuje się za pomocą różnych technik mierzenia ludzkiej inteligencji.
W przypadku komputer, poziom inteligencji może być mierzony również na wiele różnych sposób. Cześć testów IQ, które stosuje się wśród ludzi, można też zastosować wobec modeli językowych, takich jak ChatGPT i oczywiście zostało to wielokrotnie zrobione. Zobacz na przykład ten artykuł opisujący badanie ChatGPT za pomocą testu na inteligencję Wechsler Adult Intelligence Scale.
Reasumując, moim zdaniem nie ma już sensu pytać, czy AI jest inteligentne. Należy pytać, jaki poziom jest tej inteligencji w konkretnych działaniach AI. W jednych działaniach poziom ten będzie zerowy, a w innych będzie dalece przekraczający możliwości inteligencji ludzkiej.
AGI i inteligencja zdolna do odkryć naukowych
W różnorodnych dyskusjach na temat sztucznej inteligencji regularnie pojawia się sformułowanie AGI, czyli generalna sztuczna inteligencja. Najczęściej definiuje się ją jako zdolną do wykonywania większości ludzkich zadań na takim poziomie jak człowiek, lub wyższym. Stworzenie takiej inteligencji byłoby równoznaczne ze stworzeniem automatu, który zastąpi ludzką prace w większości zawodów (najpierw umysłowych, a wraz z upowszechnieniem się robotów, także fizycznych).
Jednak nie zastępowanie ludzkiej pracy jest tym, w czego oczekują od AGI najbardziej surowi komentatorzy. Ostatecznym dowodem powstania ogólnej sztucznej inteligencji ma być zdolność do dokonywania odkryć naukowych. Tu przypominam raz jeszcze przytaczane wcześniej stwierdzenie profesora Dragana, który definiując inteligencję wskazywał odkrycia naukowe Newtona, w których genialny naukowiec wykorzystywał umiejętność odnajdywania analogii.
Przeróżne są predykcje co do tego, kiedy taka inteligencja powstanie. Niektórzy przewidują ją już w ciągu zaledwie kilku, a inni kilkudziesięciu lat. Pesymiści jako główne wyzwanie przedstawiają omawiany wcześniej brak rozumowania w trakcie etapu inferencji oraz halucynacje, czyli w uproszczeniu generowanie nieprawdziwych lub nieprawdopodobnych treści.
Podsumowanie - przestrzeń fazowa inteligencji
Jak widzisz, definicji inteligencji może być wiele. Najczęściej się uzupełniają albo jedne są szersze a drugie węższe. Wiele też może być poziomów rozwoju inteligencji.
Najbardziej ogólna i obejmująca wszystkie pozostałe, to definicja Jacka Dukaja – umiejętność posługiwania się symbolami. Ta definicja jest mi najbliższa m.in. dlatego, że mam nieodparte wrażenie, że powstanie życia, już na poziomie cząsteczek aminokwasów i później pierwszych komórek, jest przejawem jakiejś głębokiej inteligencji zaszytej w istocie rzeczywistości.
Do dziś najwybitniejsi, najbardziej inteligentni naukowcy, wsparci swoimi najdroższymi narzędziami badawczymi, nie są w stanie zrozumieć i odtworzyć procesu powstania życia. To właśnie tajemniczość i niesamowita złożoność życia na poziomie wielokomórkowym skłania mnie do przekonania, że życie samo w sobie jest inteligentne. Nasza ludzka inteligencja może być jedynie wytworem tej głębszej, fundamentalnej inteligencji, której być może nigdy nie będziemy w stanie w pełni zrozumieć.
Rezonuje ze mną niezwykle też wcześniej cytowane stwierdzenie Dukaja, które na koniec przytoczę raz jeszcze:
Jakie jest prawdopodobieństwo, że nasze rozumienie inteligencji, jest wzorcowym dla inteligencji w ogóle? Wyobraźmy sobie przestrzeń fazową, w której mamy tyle wymiarów, ile jest możliwych zmiennych dla zbudowania inteligencji w ogóle i w tej przestrzeni fazowej mamy jeden punkcik i to jest inteligencja taka, jaką posiada homo sapiens. Jakie jest prawdopodobieństwo, że to jest optymalna forma inteligencji, że żadna inna jej nie pobije? Jeżeli po osiągnięciu technologicznej osobliwości pozwolimy, aby nasza sztuczna inteligencja budowała sobie kolejne, lepsze jej formy, to logicznie poruszając się po tej przestrzeni fazowej będzie oddalać się w niej od inteligencji homo sapiens ku coraz dziwniejszym obcym formom inteligencji. W przeciwnym wypadku musielibyśmy uznać, że wszechświat jest antropiczny. Czyli że powstał w takiej kombinacji założeń, praw fizyki, cząstek elementarnych, prędkości światła i tak dalej, po to tylko, żeby w niej wyewoluowana ludzka inteligencja była optymalna. Czyli to jest rodzaj jakby wiary kopernikańskiej. Jeżeli w nią nie wierzymy, to logiczną konsekwencją jest to, że ludzka inteligencja jest przypadkową wersją inteligencji, która mieści się na obrzeżach przestrzeni fazowej, a optymalna jest w gdzieś w środku.
Ode mnie zaś – nie ważne jaką definicję inteligencji przyjmiemy i w jakim stopniu uznajemy dzisiejsze AI za inteligentne. Ważne, aby rozwijać i wykorzystywać sztuczną inteligencję w celu rozwiązywania problemów ludzkości, tych dużych, jak i małych.
W perspektywie demograficznej zapaści i wobec faktu poświęcania przez większość ludzi życia na pracę tylko po to, aby jako tako to życie przeżyć, automatyzacja pracy dzięki AI może być wyzwoleniem. Wobec chciwości i ograniczonej mocy ludzkiego intelektu sztuczna inteligencja może wnieść zupełnie nową jakość do zarządzania zasobami firm, państw i całej ziemi.
Amen.
Podziękowanie
Dziękuję Łukaszowi Chomątkowi za pomoc redakcyjną. Łukasz pomógł mi wyłapać wiele różnych nieścisłości lub niejasnych sformułowań, które pisząc tak długi tekst nieuchronnie musiały się pojawić 🙂
Zachęcam do obserwowania profilu Łukasza na X. Dzieli się tam przeróżnymi ciekawostkami na temat AI. Poniżej przykład z dziś:
Sztuczna inteligencja a porady finansowe. Doradza dobrze? A może puści Cię z torbami?
— Łukasz Chomątek (@ChomatekLukasz) August 20, 2024
Przetestowałem ChatGPT, Grok i Claude'a na:
- budowaniu oszczędności
- kredytach konsumpcyjnych
- kredytach hipotecznych
Zobacz gdzie dały radę, a gdzie się pomyliły. pic.twitter.com/dtWWHYZjlj
Najczęściej czytane:
- Darmowe ogłoszenia o pracę i największa lista źródeł kandydatów – największa w Polsce lista bezpłatnych i płatnych źródeł kandydatów
- Praca w HR – najnowsze oferty pracy i aktualne średnie wynagrodzenia w branży HR
- Akademia Rekrutacji – zbiór wiedzy na temat rekrutacji oraz raporty z rynku pracy.
- Gowork – jak reagować na negatywne opinie o pracodawcach – Kompleksowy poradnik dla pracodawców.
- Sztuczna inteligencja w rekrutacji i Chat GPT-3 – wszystko co musisz wiedzieć o najnowszej wersji sztucznej inteligencji i jej możliwych zastosowaniach, także w rekrutacji.
- RODO w rekrutacji – sourcing, direct search, ogłoszenia. Wszystko co musisz wiedzieć – kompleksowy poradnik RODO w rekrutacji z naciskiem na działania typu direct search / sourcing.
- Wszystko o systemach ATS – poradnik wyboru systemu rekrutacyjnego

Maciej Michalewski
Founder & CEO @ Element

Ostatnie wpisy:
Wielka reorganizacja: firmy przebudowują się wokół AI
Foundation Capital zbadało 25 firm i odkryło, że AI zmienia nie tylko narzędzia, ale całą strukturę organizacji. Cztery role pozostaną ludzkie.

Social Media polaryzują. AI depolaryzuje?
Social Media polaryzują. AI depolaryzuje? Wprowadzenie Niedawno chwaliłem Groka za fakt, że najmniej halucynuje i jest najmniej politycznie poprawny. Teraz mamy kolejne dane, które uzupełniają

Robot z polskim rodowodem, który wkręca śruby szybciej od człowieka
Robot z polskim rodowodem, który wkręca śruby szybciej od człowieka Kiedy mówimy o automatyzacji, większość ludzi myśli o chatbotach, generatorach obrazów i asystentach programowania. Tymczasem

Wiersze AI podobają się bardziej niż poezja Szekspira
Wiersze AI podobają się bardziej niż poezja Szekspira Wprowadzenie Badanie opublikowane w Scientific Reports (Nature) dostarczyło wyników, które powinny zainteresować każdego, kto uważa, że ludzką

Trzy narzędzia, które mierzą wpływ AI na rynek pracy
Trzy narzędzia, które mierzą wpływ AI na rynek pracy Wprowadzenie Dyskusja o wpływie AI na rynek pracy toczy się od lat, ale dopiero niedawno wyszła

Rynek pracy w Polsce: 238 tysięcy ofert i widmo jobless recovery
W lutym 2026 pracodawcy opublikowali 238 tys. ofert pracy – o 7% mniej niż rok temu. Analiza 69. edycji raportu Grant Thornton i komentarz CEO Element.